What basically happens:
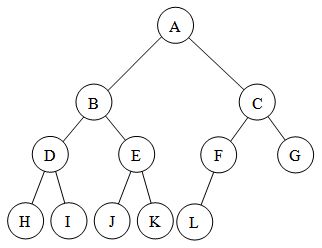
The search starts at the root node(A), and continues to travel down until it reaches a leaf node. Once it hits a leaf node, it goes a step until it can travel downwards again. This continues until it has either found what it was looking for, or until it has explored all of the nodes and found nothing. The path happens this way: (A, B, D, H, I, E, J, K, C, F, L, G)
What specifically happens:
Let's say our goal is to find G.
The search starts with the root node(A) and pushed into the stack, and continues to travel down until it reaches a leaf node. A leaf node is a node that does not have any children. At every step it checks to see if the node has already been explored. If it has been explored, it is simply ignored and continues looking in the stack. If the node has not been explored, it adds any children(that have not been explored) into the stack and adds itself to the explored list. If it hasn't found the goal, then it continues to search until it has found the goal or that the tree is all explored. Here are some of the steps:
1. A goes down B, D, and stops at H. Explored list = [A, B, D, H] Stack = [C, E, I]
2. H is a leaf so it doesn't add any children to the stack, I is popped off and added to the explored list.
Explored list = [A, B, D, H, I] Stack = [C, E]
3. I also doesn't have any children to add to stack, E gets popped off. It's added to explored and its children added to the stack.
Explored list = [A, B, D, H, I, E] Stack = [C, K, J]
4. J is popped off the stack. Because it is a leaf no children are added to the stack. Same thing happens with K.
Explored list = [A, B, D, H, I, E, J, K] Stack = [C]
5. C is popped off the stack and any of its unexplored children are added to the stack.
Explored list = [A, B, D, H, I, E, J, K, C] Stack = [G, F]
6. F is popped off the stack and, any unexplored children added.
Explored list = [A, B, D, H, I, E, J, K, C, F] Stack = [G, L]
7. L is popped off the stack and there are no children to add to the stack.
Explored list = [A, B, D, H, I, E, J, K, C, F, L] Stack = [G]
8. G is popped off the stack and because our goal was to find G, we stop our search.
Imagine that there is a search for M. What would happen? The algorithm should return something that signifies nothing was found.
Why do we need an Explored list?
The reason that we would need an explored list is to prevent already traversed nodes from being rechecked, and prevent its children from being added back into the stack. Without the explored list the algorithm would end up in a loop forever.
Just like looking for something in the grocery store, you wouldn't want to go back to an aisle you already looked in, because you remember that you've looked there already.
I hope this clears up any muddy ideas you have about this search algorithm. Feel free to let me know if I've made any errors, grave or not.


0 comments:
Post a Comment