Given a string containing just the characters '(', ')', '{', '}', '[' and ']', determine if the input string is valid.
The brackets must close in the correct order, "()" and "()[]{}" are all valid but "(]" and "([)]" are not.
First of all, if this string has an odd number of characters, we know already that it isn't valid.
The brackets must close in the correct order, "()" and "()[]{}" are all valid but "(]" and "([)]" are not.
class Solution(object):
def isValid(self, s):
if len(s) % 2 == 1:
return False
Go through each character, and if they are open characters(open parens, open bracket, open curlies), push it onto a stack.
openparens = []
for i in range(len(s)):
if s[i] == '(' or s[i] == '[' or s[i] == '{':
openparens.append(s[i])
Then, if it is any closing character, pop one off of the stack and make sure it is the opening character is the corresponding type. If everything goes well we will pass through the string nicely and return True.
elif s[i] == ')':
if len(openparens) == 0 or openparens.pop() != '(':
return False
elif s[i] == ']':
if len(openparens) == 0 or openparens.pop() != '[':
return False
else:
if len(openparens) == 0 or openparens.pop() != '{':
return False
return True

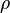 ): renames a relation or an attribute.
): renames a relation or an attribute.