Breadth-first search is a search algorithm to find something in an tree. This search algorithm utilizes a queue to keep track of all the nodes that the algorithm will explore. If you're not sure what a queue is then you should take a look at it here.
What basically happens:
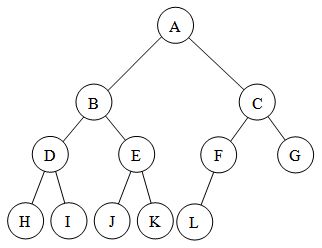
The search algorithm starts at the root node(A), and looks at each node of its children before going on.
What specifically happens:
Let's say that the goal is to find E.
The search tree starts at the root node(A) added into the queue then popped, and adds it's children into the queue. If the node it is at is not a goal, it enqueues its children into the queue. If it is the goal then the algorithm returns and stops. Here are some of the steps:
1. We start with A dequeued from the queue. Since A is not the goal and it has children, A's children are enqueued. Queue = [B, C]
2. B is dequeued from the queue and its children are enqueued. Queue = [C, D, E]
3. C is dequeued from the queue and its children are enqueued. Queue = [D, E, F, G]
4. D is dequeued from the queue and its children are enqueued. Queue = [E, F, G, H, I]
5. E is dequeued from the queue and it is our goal, so we stop.
Think about if we are searching for M. What would our path be and what would happen?
Why don't we need an explored list compared to Depth-first algorithm?
Because we search everything level by level, there is no need to keep track of explored nodes, whereas Depth-first has to go back up the tree.
The search algorithm starts at the root node(A), and looks at each node of its children before going on.
What specifically happens:
Let's say that the goal is to find E.
The search tree starts at the root node(A) added into the queue then popped, and adds it's children into the queue. If the node it is at is not a goal, it enqueues its children into the queue. If it is the goal then the algorithm returns and stops. Here are some of the steps:
1. We start with A dequeued from the queue. Since A is not the goal and it has children, A's children are enqueued. Queue = [B, C]
2. B is dequeued from the queue and its children are enqueued. Queue = [C, D, E]
3. C is dequeued from the queue and its children are enqueued. Queue = [D, E, F, G]
4. D is dequeued from the queue and its children are enqueued. Queue = [E, F, G, H, I]
5. E is dequeued from the queue and it is our goal, so we stop.
Think about if we are searching for M. What would our path be and what would happen?
Why don't we need an explored list compared to Depth-first algorithm?
Because we search everything level by level, there is no need to keep track of explored nodes, whereas Depth-first has to go back up the tree.